[Docker容器安全1] cgroup v1初识

今天学习云原生安全中docker逃逸相关内容,首先是判断是否为容器环境
cat /proc/1/cgroup | grep -qi docker && echo "Is Docker" || echo "Not Docker"
wait, 这个cgroup是啥?
相关概念
Task
Task(任务): 在 linux 系统中,内核本身的调度和管理并不对进程和线程进行区分,只是根据 clone() 时传入的参数的不同来从概念上区分进程和线程。这里使用 task 来表示系统的一个进程或线程。
Cgroup
Cgroup(控制组):cgroups 中的资源控制以 cgroup 为单位实现。Cgroup 表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个 cgroup,也可以从某个 cgroup 迁移到另一个 cgroup。
划分组的目的就是方便管理,管理Linux中任务调度的资源用的就是cgroup。另外,cgroup在不同的上下文中代表不同的意思,可以指整个Linux的cgroup技术,也可以指一个具体进程组。
Subsystem
Subsystem(子系统):cgroups 中的子系统就是一个资源调度控制器(又叫 controllers)。比如 CPU 子系统可以控制 CPU 的时间分配,内存子系统可以限制内存的使用量。以笔者使用的 Ubuntu 16.04.3 为例,其内核版本为 4.10.0,支持的 subsystem 如下( cat /proc/cgroups):
- blki:对块设备的 IO 进行限制。
- cpu:限制 CPU 时间片的分配,与 cpuacct 挂载在同一目录。
- cpuacct:生成 cgroup 中的任务占用 CPU 资源的报告,与 cpu 挂载在同一目录。
- cpuset:给 cgroup 中的任务分配独立的 CPU(多处理器系统) 和内存节点。
- devices:允许或禁止 cgroup 中的任务访问设备。
- freezer:暂停/恢复 cgroup 中的任务。
- hugetlb:限制使用的内存页数量。
- memory:对 cgroup 中的任务的可用内存进行限制,并自动生成资源占用报告。
- net_cls:使用等级识别符(classid)标记网络数据包,这让 Linux 流量控制器(tc 指令)可以识别来自特定 cgroup 任务的数据包,并进行网络限制。
- net_prio:允许基于 cgroup 设置网络流量(netowork traffic)的优先级。
- perf_event:允许使用 perf 工具来监控 cgroup。
- pids:限制任务的数量。
简单理解Subsystem就是对Linux某一资源的管理,到目前为止,Linux支持12种subsystem。
Hierarchy
Hierarchy(层级):一个hierarchy可以理解为一棵cgroup树,树的每个节点就是一个进程组,每棵树都会与零到多个subsystem关联。在一颗树里面,会包含Linux系统中的所有进程,但每个进程只能属于一个节点(进程组)。系统中可以有很多颗cgroup树,每棵树都和不同的subsystem关联,一个进程可以属于多颗树,即一个进程可以属于多个进程组,只是这些进程组和不同的subsystem关联。目前Linux支持12种subsystem,如果不考虑不与任何subsystem关联的情况(systemd就属于这种情况),Linux里面最多可以建12颗cgroup树,每棵树关联一个subsystem,当然也可以只建一棵树,然后让这棵树关联所有的subsystem。当一颗cgroup树不和任何subsystem关联的时候,意味着这棵树只是将进程进行分组,至于要在分组的基础上做些什么,将由应用程序自己决定,systemd就是一个这样的例子。
这个 hierarchy 的定义实在是有点抽象,所以我决定用个例子帮助理解。
举个栗子
我们假设有一个应用,它由两部分组成:一个前端服务和一个后端服务。我们想要确保后端服务(处理数据和逻辑的核心部分)总是有足够的内存(memory)资源,而前端服务(处理用户界面的部分)则在资源紧张时可以被适当限制。
创建顶层结构
既然要限制内存,我们我们肯定要在memory这个子系统下创建我们应用的cgroup。于是我们创建了一个顶层cgroup(root_group)代表整个应用
# 创建顶层 cgroup
mkdir /sys/fs/cgroup/memory/root_group
其实这里隐含了一层意思,我们在一颗树上的根结点上新建了一个子结点,而这棵树是与memory subsystem相关联的。
创建子cgroup
在 root_group 下,我们创建两个子 cgroup:backend_group 和 frontend_group,其中:
- backend_group:用于后端服务,确保核心服务有足够的资源。
- frontend_group:用于前端服务,其资源可以被适当限制以保证后端服务的资源需求。
# 创建子 cgroup
mkdir /sys/fs/cgroup/memory/root_group/backend_group
mkdir /sys/fs/cgroup/memory/root_group/frontend_group
设置内存限制
- backend_group:不设置硬性限制,或者设置一个较高的限制,确保后端服务有足够的资源可用。
- frontend_group:设置较低的内存限制,比如 50MB,确保在资源紧张时,前端服务的资源使用被适当限制。
# 设置前端服务的内存限制为 50MB
echo 52428800 > /sys/fs/cgroup/memory/root_group/frontend_group/memory.limit_in_bytes
将进程添加到相应的 cgroup 中
- 将后端服务的进程 PID 添加到 backend_group。
- 将前端服务的进程 PID 添加到 frontend_group。
# 添加进程到 cgroup
echo 1234 > /sys/fs/cgroup/memory/root_group/frontend_group/cgroup.procs
# 假设后端服务的 PID 为 5678
echo 5678 > /sys/fs/cgroup/memory/root_group/backend_group/cgroup.procs
这两个进程就加入了与内存相关联的子系统的这棵树下的具体的节点(cgroup),当然他们也可以加入到其他不同的树中,受这些树所关联的子系统的控制。
cgroups的文件系统接口
cgroups 以文件的方式提供应用接口,我们可以通过 mount 命令来查看 cgroups 默认的挂载点:mount | grep cgroup
[root@xdd ~]# mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
执行这个命令后返回的内容解释如下:
- 第一行:
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)显示了一个tmpfs(临时文件系统)被挂载在/sys/fs/cgroup。- cgroup:文件系统的根目录
- tmpfs: 意味着 cgroup 的元数据和控制文件存储在内存中,而不是磁盘上,这样可以提高访问速度。
- ro,nosuid,nodev,noexec,mode=755:描述了挂载的选项,例如只读(ro)、不允许 set-user-identifier 或 set-group-identifier 权限(nosuid)、禁止执行设备文件(nodev)、禁止执行任何二进制文件(noexec),以及目录的访问权限(mode=755)。
- 第二行:
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)这里涉及到 systemd 管理的 cgroup。在使用 systemd 系统的操作系统中,/sys/fs/cgroup 目录都是由 systemd 在系统启动的过程中挂载的,并且挂载为只读的类型。换句话说,系统是不建议我们在 /sys/fs/cgroup 目录下创建新的目录并挂载其它子系统的。这一点与之前的操作系统不太一样(🤔)。 - 其余行:每个 cgroup 子系统的挂载点,对应了可以控制的资源类型。比如
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup表示 CPU 时间和 CPU 使用统计的 cgroup 子系统共同挂载在/sys/fs/cgroup/cpu,cpuacct。
/sys/fs/cgroup及其子目录memory结构
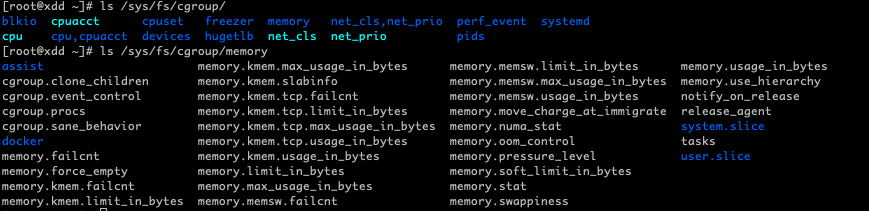
/sys/fs/cgroup 目录下是各个子系统的根目录。memory 目录下的文件就是 cgroups 的 memory 子系统中的根级设置。比如 memory.limit_in_bytes 中的数字用来限制进程的最大可用内存,memory.swappiness 中保存着使用 swap 的权重等等。
进程所属的cgroup
可以通过 /proc/[pid]/cgroup 来查看指定进程属于哪些 cgroup:
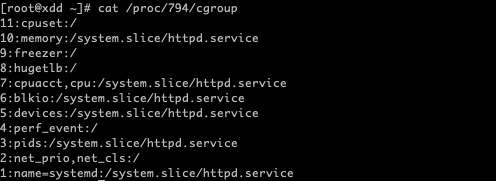
这个 cgroup 信息显示了进程 ID 为 794 的进程所属的 cgroup 配置。每一行都代表该进程在不同 cgroup 子系统下的归属情况。格式通常为 层级编号:子系统名称:路径:
- 层级编号:cgroup 树的 ID, 和 /proc/cgroups 文件中的 ID 一一对应。
- 子系统名称:表示 cgroup 控制的资源类型。例如 cpu、memory、blkio 等。有些行中出现的是组合子系统,如 cpuacct,cpu,意味着这些资源控制器被组合在一起管理。
- 路径:显示进程所属的 cgroup 在 cgroup 文件系统中的路径。例如,/system.slice/httpd.service 表示进程属于名为 httpd.service 的服务单元管理的 cgroup。路径 / 表示根 cgroup,也就是最顶层的 cgroup,它通常用于未被特别分配到其他特定 cgroup 的进程。
PS.可以通过查看/proc/cgroups(since Linux 2.6.24)知道当前系统支持哪些subsystem,下面是一个例子
#subsys_name hierarchy num_cgroups enabled
cpuset 11 1 1
cpu 3 64 1
cpuacct 3 64 1
blkio 8 64 1
memory 9 104 1
devices 5 64 1
freezer 10 4 1
net_cls 6 1 1
perf_event 7 1 1
net_prio 6 1 1
hugetlb 4 1 1
pids 2 68 1
从左到右,字段的含义分别是:
- subsystem的名字
- subsystem所关联到的cgroup树的ID,如果多个subsystem关联到同一颗cgroup树,那么他们的这个字段将一样,比如这里的cpu和cpuacct就一样,表示他们绑定到了同一颗树。如果出现下面的情况,这个字段将为0:
- 当前subsystem没有和任何cgroup树绑定
- 当前subsystem已经和cgroup v2的树绑定
- 当前subsystem没有被内核开启
- subsystem所关联的cgroup树中进程组的个数,也即树上节点的个数
- 1表示开启,0表示没有被开启(可以通过设置内核的启动参数“cgroup_disable”来控制subsystem的开启).
关于1:name=systemd:/system.slice/httpd.service(🤔):
- name=systemd: 这部分说明这个特定的 cgroup 层级是由 systemd 使用的,而不是由单一的资源类型(如 cpu 或 memory)直接控制。name=systemd 表示这个层级是专门为 systemd 使用而设置的一个命名层级,用来管理和组织由 systemd 控制的服务。这是 cgroup v1 中支持为各种不同的目的创建命名层级的功能之一。
- /system.slice/httpd.service: 这部分显示了 cgroup 在文件系统中的路径。这个路径指示进程属于 httpd.service 服务,这是一个 systemd 服务单元的名称。在 systemd 的体系中,system.slice 是一个用于组织系统服务的分片(slice),而 httpd.service 则是运行在这个分片中的特定服务。
- 与其他行相比,这行信息的特殊之处在于它直接关联到 systemd,而不是标准的资源类型子系统。systemd 使用它自己的 cgroup 层级来组织和管理服务,这使得 systemd 能够利用 cgroup 提供的功能来执行诸如服务启动、停止、重启以及资源限制等操作。
cgroup测试
安装cgroups工具
Centos下安装cgroup 工具:
- 安装 libcgroup
yum install libcgroup
- 安装 libcgroup-tools
yum install libcgroup-tools
- 验证安装,使用 cgget 命令查看当前 cgroup 配置
cgget -g cpu:/
测试:限制进程可用的 CPU
在/sys/fs/cgroup/cpu 目录下新建一个名称为 skky_cpu 的目录:
mkdir /sys/fs/cgroup/cpu/skky_cpu
cgroups 的文件系统会在创建文件目录的时候自动创建相关的配置文件

在设置skky_cpu前,先看下默认的相关配置:
[root@xdd ~]# cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000
[root@xdd ~]# cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
-1
- **cpu.cfs_period_us:**表示调度周期的长度,以微秒(us)为单位。在这个周期内,cgroup 可以被限制只能使用一定量的 CPU 时间,必须与cfs_quota_us配合使用。
- cpu.cfs_quota_us :设定周期内最多可使用的时间,这里的配置指 task 对单个 cpu 的使用上限。假如cpu.cfs_period_us 被设置为 100000(即 100 毫秒),而 **cpu.cfs_quota_us **被设置为 10000(即 10 毫秒)。这意味着,在每 100 毫秒的时间窗口中,属于该 cgroup 的进程总共能使用最多 10 毫秒的 CPU 时间。这相当于分配了 10% 的 CPU 时间给该 cgroup。而默认配置中这个值为-1,表示表示不对该 cgroup 的 CPU 时间使用量做限制。
现在我们吧skky_cpu的 CPU 周期限制为总量的十分之一:
echo 10000 > /sys/fs/cgroup/cpu/skky_cpu/cpu.cfs_quota_us
用一个CPU 密集型的程序测试:
void main(){
unsigned int i, end;
end = 1024 * 1024 * 1024;
for(i = 0; i < end; )
{
i ++;
}
}
编译并执行:
gcc cputime.c -o cputime
time ./cputime
time cgexec -g cpu:skky_cpu ./cputime
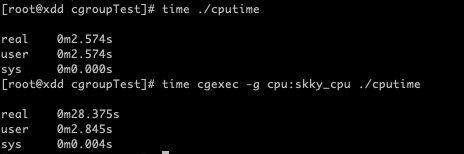
可以看到程序正常运行的时间为2.5s,而添加 cgroup 的运行时间为28s。
使用Cgroup判断容器环境
在docker容器pid为1的进程,通常是容器的初始化进程
root@662559eb1259:/# cat /proc/1/cgroup
11:cpuset:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
10:memory:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
9:freezer:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
8:hugetlb:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
7:cpuacct,cpu:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
6:blkio:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
5:devices:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
4:perf_event:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
3:pids:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
2:net_prio,net_cls:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
1:name=systemd:/docker/662559eb1259dd29170985293fdcc5465cca5ac1c655bba37aa364cb988670e9
从这个响应可以看到,在docker容器中所有cgroup子系统的路径都是/docker/[容器ID],这就是使用cat /proc/1/cgroup可以判断当前是否为容器环境的原因。
cgroup v2
cgroup v2 是对最初的 cgroup(控制组)机制的重大改进和简化,在v2中不再为每种资源类型(如 CPU、内存等)创建独立的层级,而是引入单一的层级系统,所有类型的资源都在这个统一的层级下管理。

关于cgroup v2 具体的细节这里先不关心,简单说下对docker的影响。使用cat /proc/1/cgroup的输出为:
root@015731e32eb9:/# cat /proc/1/cgroup
0::/
0: 这个部分表示 cgroup 的层级编号。在 cgroup v2 中,由于只有一个统一的层级,所以这个编号是0。这是一个标志性的变化,表明系统使用的是 cgroup v2。::这个部分原本在 cgroup v1 中用于分隔层级编号和子系统列表(例如 cpu, memory)。在 cgroup v2 中,由于不再需要指定子系统(所有资源控制都在一个层级中),因此这里不再显示具体的子系统名称,仅用冒号表示分隔。/这个部分表示 cgroup 的路径。在这个上下文中,/指的是根 cgroup,也就是整个 cgroup 层级的最顶层。进程号为 1 的进程(系统的初始化进程,通常是 systemd 或 init)属于这个最顶层的 cgroup,表示它有权管理和控制系统中的所有其他进程和资源。
宿主机上有关docker容器的cgroup信息在/sys/fs/cgroup/system.slice/目录下,格式为
/sys/fs/cgroup/system.slice/docker-<longid>.scope/
如果要在 cgroup v2 查出 docker 容器的ID号,可以查看/proc/1/mountinfo文件,里面是进程的挂载点信息
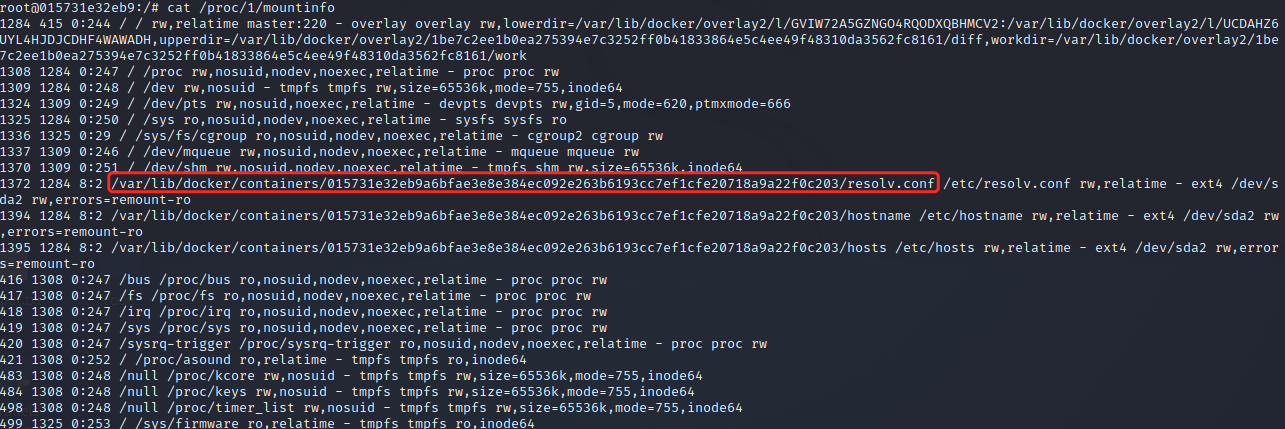
参考文章
https://www.cnblogs.com/sparkdev/p/8296063.html
https://segmentfault.com/a/1190000006917884
https://mikechengwei.github.io/2020/06/03/cgroup%E5%8E%9F%E7%90%86/
https://stackoverflow.com/questions/68816329/how-to-get-docker-container-id-from-within-the-container-with-cgroup-v2
https://zone.huoxian.cn/d/990